Βάσεις Δεδομένων και ο ρόλος τους στην ομαλή λειτουργία του Κέντρου Λήψης
Πολλές φορές στην προσπάθεια εύρεσης του «σωστού» λογισμικού στα ΚΛΣ οι ενδιαφερόμενοι επικεντρώνονται στις δυνατότητες της εκάστοτε εφαρμογής σε σχέση με τη μια ή την άλλη περίπτωση ή συγκρίνουν οικονομικά μεγέθη, παραμερίζοντας τη βασικότερη παράμετρο επιλογής τους, δηλαδή τις «βάσεις δεδομένων».



Πληροφορία
Το Κέντρο Λήψης Σημάτων Συναγερμού (ΚΛΣ) αποτελεί κατά βάση ένα δίαυλο συλλογής και διαχείρισης Πληροφοριών. Με τον όρο «πληροφορία», εννοούμε τα αποστελλόμενα σήματα συναγερμού τα οποία περιέχουν δεδομένα και πληροφορίες τόσο της κατάστασης του συναγερμού όσο και των συμβάντων που λαμβάνουν χώρα. Σε ένα ΚΛΣ τα εισερχόμενα σήματα είναι ανάλογα των συνδεδεμένων συστημάτων. Έτσι, ένα μεσαίου μεγέθους ΚΛΣ μπορεί να φτάσει το ένα εκατομμύριο σήματα το μήνα, λαμβανομένου υπόψη των εσωτερικών σημάτων και των αναγνωρίσεων κλήσης. Καταλαβαίνουμε πόσο σημαντικό είναι ό όγκος αυτών των δεδομένων να ταξινομηθεί, να φυλαχθεί και να μπορεί να ανακτηθεί -ανά πάσα στιγμή- με ασφάλεια, ταχύτητα και αξιοπιστία. Την εργασία αυτή καλείται να επιτελέσει το λογισμικό του ΚΛΣ με την χρήση της κατάλληλης βάσης δεδομένων.
Πολλές φορές στην προσπάθεια εύρεσης του «σωστού» λογισμικού οι ενδιαφερόμενοι επικεντρώνονται στις δυνατότητες της εκάστοτε εφαρμογής σε σχέση με τη μια ή την άλλη περίπτωση ή συγκρίνουν οικονομικά μεγέθη, παραμερίζοντας τη βασικότερη παράμετρο επιλογής τους, δηλαδή τις «βάσεις δεδομένων». Η σημασία αυτή της παραμέτρου γίνεται αντιληπτή πολύ αργά, όταν ο αριθμός των συνδρομητών πολλαπλασιάζεται και το ΚΛΣ βρίσκεται σε πλήρη αδυναμία να καλύψει τις βασικές του λειτουργίες.
- Πώς όμως ένας επιχειρηματίας θα διαλέξει το λογισμικό με τη σωστή βάση δεδομένων;
- Πώς είναι σίγουρος ότι θα επιτελέσει το σκοπό της άριστα παρέχοντάς του ασφάλεια, ταχύτητα και προσβασιμότητα;
- Πώς ξέρει ότι δεν θα τον προδώσει υπό το βάρος ενός αυξανόμενου όγκου δεδομένων, τη στιγμή μάλιστα που θα την χρειάζεται περισσότερο, δηλαδή, τη στιγμή που θα έχει καταφέρει να αυξήσει τους πελάτες του?
Πριν εξετάσουμε κάποιες τεχνικές που θα έδιναν μια απάντηση στα παραπάνω ερωτήματα, σκόπιμο είναι να αναφερθούμε στα είδη των βάσεων δεδομένων, τις ιδιαιτερότητες που παρουσιάζουν και τον τρόπο διατήρησής τους σε «υγιή» κατάσταση.
Βάσεις δεδομένων (Databases)
Ως «Βάσεις Δεδομένων» ορίζουμε ένα σύνολο πληροφοριών δομημένων κατά τέτοιο τρόπο ώστε η ανάκτησή τους να είναι άμεση, απλή και αποτελεσματική.
Οι βάσεις δεδομένων μπορεί να είναι απλά αρχεία με οργανωμένα ομοειδή στοιχεία μέχρι και ένα σύμπλεγμα αρχείων και εφαρμογών. Η εξέλιξή τους ακολούθησε παράλληλη πορεία με την εξέλιξη των υπολογιστών, και των δικτύων. Η ραγδαία αύξηση του όγκου δεδομένων οδήγησε στην εύρεση ολοένα και νεότερων και ταχύτερων και αποδοτικότερων τεχνικών προσπέλασης όπως επίσης και μεθόδων διατήρησης των φυσικών θέσεων των μαγνητικών μέσων όπου φυλάσσονται τα δεδομένα.
Για να κατανοήσουμε τον τρόπο λειτουργίας των βάσεων δεδομένων θα πρέπει να τις προσεγγίσουμε από τρεις διαφορετικές πλευρές:
1. Τρόπος ταξινόμησης των δεδομένων (Data Models)
2. Τρόπος φύλαξης στα μαγνητικά μέσα
3. Τεχνολογίες προσπέλασης
1.Τρόπος ταξινόμησης των Δεδομένων (Data Models)
Σχεδιάζοντας τον τρόπο ταξινόμησης των δεδομένων καλούμαστε να επιλέξουμε το κατάλληλο μοντέλο (data model) μεταξύ δυο περιπτώσεων:
Α) μοντέλα βασισμένα σε εγγραφές (record based models)
Β) μοντέλα βασισμένα σε αντικείμενα (object based models)
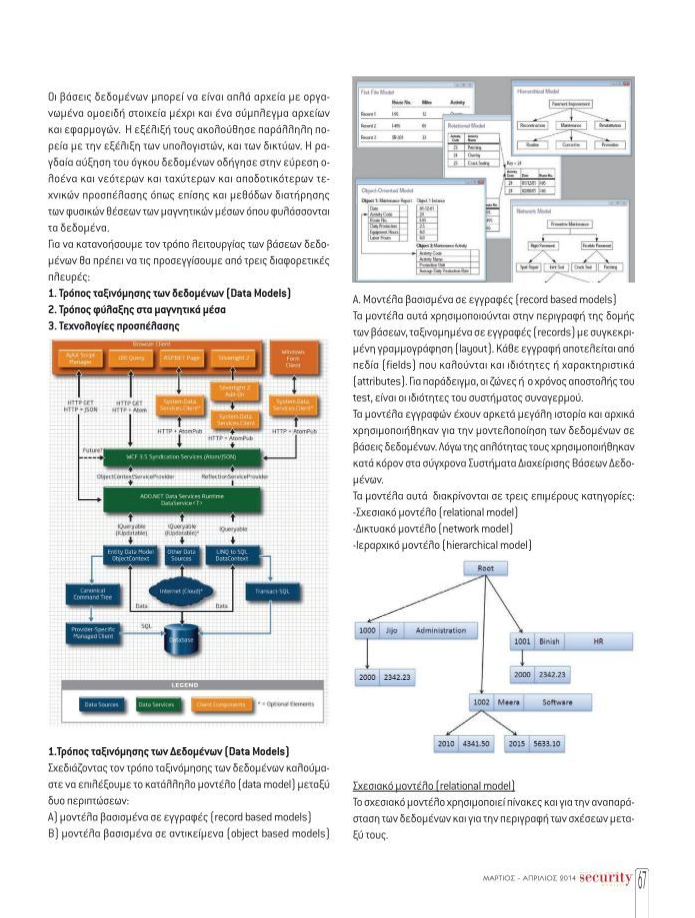
A. Mοντέλα βασισμένα σε εγγραφές (record based models)
Τα μοντέλα αυτά χρησιμοποιούνται στην περιγραφή της δομής των βάσεων, ταξινομημένα σε εγγραφές (records) με συγκεκριμένη γραμμογράφηση (layout). Κάθε εγγραφή αποτελείται από πεδία (fields) που καλούνται και ιδιότητες ή χαρακτηριστικά (attributes). Για παράδειγμα, οι ζώνες ή ο χρόνος αποστολής του test, είναι οι ιδιότητες του συστήματος συναγερμού.
Τα μοντέλα εγγραφών έχουν αρκετά μεγάλη ιστορία και αρχικά χρησιμοποιήθηκαν για την μοντελοποίηση των δεδομένων σε βάσεις δεδομένων. Λόγω της απλότητας τους χρησιμοποιήθηκαν κατά κόρον στα σύγχρονα Συστήματα Διαχείρισης Βάσεων Δεδομένων.
Τα μοντέλα αυτά διακρίνονται σε τρεις επιμέρους κατηγορίες:
-Σχεσιακό μοντέλο (relational model)
-Δικτυακό μοντέλο (network model)
-Ιεραρχικό μοντέλο (hierarchical model)
Σχεσιακό μοντέλο (relational model)
Το σχεσιακό μοντέλο χρησιμοποιεί πίνακες και για την αναπαράσταση των δεδομένων και για την περιγραφή των σχέσεων μεταξύ τους.
Κάθε πίνακας αποτελείται από τις στήλες (columns) οι οποίες με τη σειρά τους περιγράφουν τις ιδιότητες (fields, attributes). Το μοντέλο αυτό είναι το πλέον εύχρηστο και συχνότερα χρησιμοποιούμενο.
Δικτυακό μοντέλο (network model)
Εδώ, τα δεδομένα μοντελοποιούνται με εγγραφές ενώ οι σχέσεις μεταξύ των δεδομένων περιγράφονται με συνδέσμους (links, pointers) σχηματίζωντας μια δομή γραφήματος (graph).
Ιεραρχικό μοντέλο (hierarchical model)
Παρόμοιο με το δικτυακό μοντέλο με τη διαφορά ότι οι συσχετίσεις δεδομένων περιγράφονται από ιεραρχικές δενδρικές δομές.
B. Mοντέλα βασισμένα σε αντικείμενα (object based models)
Το αντικείμενο (object) στα μοντέλα αυτά αντιπροσωπεύει μια οντότητα του πραγματικού κόσμου η οποία έχει συγκεκριμένες ιδιότητες και σχετίζεται με άλλες οντότητες (οντοκεντρικό σύστημα). Παρά τη «μεταφυσική» περιγραφή του μοντέλου, η εξήγηση είναι αρκετά προσιτή.
Σε αυτή την κατηγορία των μοντέλων μας ενδιαφέρουν δύο υποκατηγορίες:
1. Μοντέλο οντοτήτων συσχετίσεων (entity -relationship)
2. Αντικειμενοστραφές μοντέλο (object-oriented)
1. Μοντέλο οντοτήτων συσχετίσεων (entity -relationship)
Στο μοντέλο συσχετίσεων χρησιμοποιούνται οι «οντότητες», «ιδιότητες» και «συσχετίσεις» με την παρακάτω περίπου προσωποποίηση:
- Ο πελάτης είναι μια «οντότητα» με συγκεκριμένες ιδιότητες (όνομα, επίθετο, διεύθυνση)
- Το σύστημα συναγερμού είναι μια άλλη «οντότητα» και αυτό με συγκεκριμένες ιδιότητες (κωδικό επικοινωνίας, χρόνο αποστολής test, κατάσταση οπλισμού/αφοπλισμού)
- Η ζώνη ενός συστήματος είναι μια ακόμα «οντότητα» με ιδιότητες όπως ο αριθμός, η περιγραφή κλπ.
Για να μπορέσουμε όμως να προσδιορίσουμε το σύστημα συναγερμού ενός πελάτη θα πρέπει να βρούμε τον συνδετικό τους κρίκο. Τον κρίκο δηλαδή που συνδέει μεταξύ τους τις «οντότητες». Αυτός ο κρίκος λέγεται «συσχέτιση» και προσδιορίζει τον τρόπο σύνδεσης δύο η περισσοτέρων «οντοτήτων».
2. Αντικειμενοστραφές μοντέλο (object-oriented)
Την πλέον εξελιγμένη μορφή δεδομένων και μάλιστα αυτόνομων, αποτελεί το συγκεκριμένο μοντέλο.
Το αντικειμενοστραφές μοντέλο δεδομένων χρησιμοποιεί «αντικείμενα», «ιδιότητες» (properties) και μεθόδους (methods) για την περιγραφή και προσπέλαση δεδομένων.
Τα «αντικείμενα» επικοινωνούν μεταξύ τους μέσω των «μεθόδων» και επειδή το κάθε «αντικείμενο» αποκτάει «οντότητα» μετά την δημιουργία του με δικό του κώδικα προγράμματος, αποκτά και δυνατότητα αυτοελέγχου και αυτοπροστασίας των δεδομένων του. Όταν δε, επιτευχθεί ο σκοπός του αυτοκαταστρέφεται.
2. Τρόπος φύλαξης στα μαγνητικά μέσα
Κάθε βάση δεδομένων φυλάσσει τα δεδομένα της σε κάποιο μαγνητικό, οπτικό ή άλλο μέσο, υπό μορφή αρχείων. Ο εντοπισμός αυτών των αρχείων είναι λιγότερο ή περισσότερο δύσκολος ανάλογα με τον τύπο των βάσεων.
Οι πρώτες τεχνολογίες ταχείας προσπέλασης (random access) που χρησιμοποιήθηκαν, αφορούσε αρχεία που δεν περιείχαν πληροφορίες για την δομή των εγγραφών, κάτι που γνώριζε μόνο η εφαρμογή που τα χρησιμοποιούσε.
Ένα άλλο τύπο φύλαξης αποτέλεσε επίσης και η χρήση των αρχείων CSV (Character Separated Values) με οπτική αναγνώριση των δεδομένων.
Σήμερα ωστόσο, χρησιμοποιείται η πλέον εξελιγμένη μορφή αρχείων που δεν είναι άλλη από τα αρχεία .xml τα οποία βρίσκουν τεράστια εφαρμογή και στο διαδίκτυο. Τα αρχεία .xml μπορούν να χρησιμοποιηθούν για
μεταφορά και φύλαξη των Βάσεων Δεδομένων και επιπλέον είναι εύκολα αναγνωρίσιμα.
Παράγοντες όπως, ο μεγάλος όγκος δεδομένων, ο μεγάλος αριθμός των χρηστών που τα προσπελαύνουν και η διασπορά τους σε διαφορετικούς τόπους (χώρες) δημιούργησε την ανάγκη του Clustering ή την ύπαρξη Διασύνδεσης Βάσεων μεταξύ πολλών Συστημάτων Διαχείρισης Βάσεων Δεδομένων (ΣΔΒΔ).
3.Τεχνολογίες προσέλασης
Με τον όρο «προσπέλαση δεδομένων» εννοούμε τη δυνατότητα που έχουμε να πάρουμε μια πληροφορία τη στιγμή που τη χρειαζόμαστε και να την τροποποιήσουμε ή να την φυλάξουμε στη Βάση Δεδομένων.
Οι τεχνικές προσπέλασης που μας ενδιαφέρουν είναι τρεις:
1. Απευθείας διαχείριση των δεδομένων από την εφαρμογή (txt,csv,xml,sql)
2. Διαχείριση των δεδομένων μέσω ενός διαμεσολαβητή (MsJet, odbc, portable DBs)
3. Διαχείριση των δεδομένων μέσω τεχνολογίας TCP/IP (MSQL, MySQL, ORACLE, POSTGREE κ.α)
1. Απευθείας διαχείριση των δεδομένων από την εφαρμογή
Είναι η παλαιότερη μέθοδος και πλέον τη χρησιμοποιούμε μόνο για την δημιουργία αντιγράφων ή την μεταφορά δεδομένων από μια βάση δεδομένων σε μια άλλη.
Η χρήση των δομών των αρχείων τύπου SQL, XML, είναι οι πλέον διαδεδομένες και αποτελούν το πιο ενδεδειγμένο τρόπο μεταφοράς και φύλαξης αρχείων τόσο, με την χρήση τεχνολογιών FTPs (File Transfer Protocols) ανάμεσα σε διαφορετικά λειτουργικά συστήματα όσο, και TCP/IP πρωτοκόλλων μέσω διαδικτύου.
2. Διαχείριση των δεδομένων μέσω ενός διαμεσολαβητή
Ο πιο διαδεδομένος τρόπος προσπέλασης για μικρού και μεσαίου όγκου δεδομένα. Παρέχεται ευκολία στη μεταφορά και τη δημιουργία αντιγράφων της Βάσης Δεδομένων.
Ωστόσο, στα αρνητικά αυτής της τεχνολογίας πρέπει να σημειώσουμε την ταχύτητα προσπέλασης (όταν ξεφεύγουμε από το τοπικό δίκτυο), τον όγκο των εγγραφών που περιορίζεται στα 3-5 εκατομμύρια, τους περιορισμούς που προκύπτουν από τα δικαιώματα χρήσης του συστήματος καθώς και την αυξημένη συχνότητα συντήρησης των βάσεων.
3. Διαχείριση των δεδομένων μέσω τεχνολογίας TCP/IP
Μετά από μια δεκαετή εξελικτική πορεία, η διαχείριση των δεδομένων μέσω τεχνολογίας TCP/IP ενδείκνυται για εφαρμογές με μεγάλο όγκο δεδομένων προσφέροντας ταχύτητα, αξιοπιστία και ευελιξία στη εφαρμογή του μεγαλύτερου δυνατού επιπέδου ασφάλειας.
Η προσπέλαση των δεδομένων επιτυγχάνεται με ένα σύνολο εντολών SQL (Structured Query Language). H φυσική θέση των Συστημάτων Διαχείρισης Βάσεων Δεδομένων μπορεί να είναι μια διεύθυνση δικτύου ή , ένα domain, με αποτέλεσμα ο χρήστης να μη γνωρίζει την ακριβή θέση τους αφού τα δεδομένα μπορεί να βρίσκονται είτε σε μια Βάση Δεδομένων είτε, σε ένα πλήθος Βάσεων Δεδομένων διασκορπισμένα στο δίκτυο ή στο διαδίκτυο (Data Clustering Cloud Servers).
Συμπεράσματα
Η σωστή επιλογή και αξιοποίηση επομένως μιας Βάσεως Δεδομένων είναι το πρωταρχικό μέλημα μιας εφαρμογής που φιλοδοξεί να προσφέρει ταχύτητα και ασφάλεια δεδομένων στον κατοχό της.
Αυτό θα επιτευχθεί μόνο μέσα από βαθιά μελέτη των αναγκών της και υψηλό τεχνολογικό υπόβαθρο των κατασκευαστών της, γεγονός ωστόσο που δεν είναι εύκολα μετρήσιμο από τον αγοραστή.
Εάν θέλουμε λοιπόν να καταλήξουμε σε κάποια χρήσιμα συμπεράσματα που μπορούν να έχουν πρακτική εφαρμογή από τους αναγνώστες, θα συνοψίζαμε λέγοντας ότι, ο τεχνικός υπεύθυνος του ΚΛΣ -ο οποίος και παίζει καθοριστικό ρόλο στην ορθή επιλογή του κατάλληλου λογισμικού- πρέπει να είναι ενήμερος για τις τεχνολογίες των Βάσεων Δεδομένων, τις τεχνικές λήψης αντιγράφων και τις διαδικασίες υποστήριξης τους.
Συνοπτικά, πρέπει να δοθεί ιδιαίτερη προσοχή:
1. στη φυσική θέση των αρχείων των Βάσεων Δεδομένων
2. στις υπάρχουσες ενεργές διασυνδέσεις μεταξύ των βάσεων δεδομένων για την σωστή ενημέρωσή τους σε πραγματικό χρόνο
3. στην ύπαρξη αυτόματων διαδικασιών λήψης αντιγράφων ασφαλείας
4. στις διαδικασίες ανάκτησης μέρους ή όλων των δεδομένων από τα αντίγραφα που έχουν ληφθεί
Ασφαλώς, δεν θέλουμε να πούμε ότι επιλέγοντας μια εφαρμογή με τις σωστές Βάσεις Δεδομένων θα λύσετε όλα σας τα προβλήματα ούτε ότι η ιδανική εφαρμογή είναι αποτέλεσμα μόνο της επιλογής των σωστών Βάσεων Δεδομένων. Πιθανά «ιδανική εφαρμογή» να μην υπάρχει, αφού για τον καθένα το ιδανικό έχει και υποκειμενικές παραμέτρους βάσει των προσωπικών του πεποιθήσεων και εμπειριών. Είναι όμως σημαντικό για μια εφαρμογή να μπορεί να φτάσει το «ιδανικό» κάθε χρήστη επειδή θα έχει σχεδιαστεί κατά τέτοιο τρόπο ώστε να είναι ευέλικτη, λειτουργική και παραμετροποιήσιμη στα μέτρα του κάθε ενός ξεχωριστά. Πάνω σε αυτή τη λογική στηρίζεται και η ορθή επιλογή των Βάσεων Δεδομένων μια λογική που οφείλει να είναι σύγχρονη, να διαθέτει δικλείδες ασφαλείας και να ενσωματώνει νέες τάσεις και τεχνολογίες με τόλμη και όραμα.
Γεώργιος Σταυριανός
Φυσικός-Αναλυτής Συστημάτων
Γεν. Διευθυντής ORBIT SYSTEMS